
Qué es la codificación de caracteres
La codificación de caracteres (character encoding) es el método que permite convertir un carácter de un lenguaje natural (alfabeto) en un símbolo de otro sistema de representación, como un número, un símbolo o una secuencia de pulsos eléctricos en un sistema electrónico, aplicando una serie de normas o reglas de codificación. En este artículo vamos a centrarnos en cómo los sistemas informáticos utilizan la codificación de caracteres para convertir y representar los diferentes lenguajes escritos del mundo a una representación que dicho sistema entienda, y así poder almacenar o transmitir dicha información.
La codificación de caracteres se basa en definir tablas que indiquen el carácter en el lenguaje natural y su correspondencia en el lenguaje del sistema informático. Estas tablas se denominan conjunto de caracteres (charset o character set), mapa de caracteres (character map) o página de códigos (page code).
Conjunto de caracteres más comunes
Conjuntos de caracteres universales serían, por ejemplo, el código morse, el braile y las banderas de señales marítimas entre otros.
A continuación listamos los conjuntos de caracteres más comunes relacionados con el mundo de la tecnología y la transmisión de datos digitales. Se puede consultar el listado completo en:
http://en.wikipedia.org/wiki/Character_encoding
ASCII
El conjunto de caracteres ASCII publicado por el ANSI (American National Standard Code for Information Interchange) como estándar en 1967, se diseñó en un principio utilizando solamente 7 bits, para dejar el octavo bit para la paridad (control de errores), por lo que solamente puede representar 128 caracteres, suficientes para incluir mayúsculas y minúsculas del abecedario inglés, además de cifras, puntuación y algunos caracteres de control.
Podéis leer más sobre la historia del código y algunas curiosidades aquí.

ISO-8859
Pero ASCII no incluye los caracteres acentuados ni el comienzo de interrogación que se usa en castellano, ni tantos otros símbolos (matemáticos, letras griegas, etc.) que son necesarios en muchos contextos. Por lo que surgió la norma ISO 8859 que utiliza 8 bits y que, por tanto, permite 256 caracteres, suficientes para abarcar los caracteres de un lenguaje en concreto. En ellos, los 128 caracteres primeros son los mismos de la tabla ASCII original y los 128 siguientes se corresponden a símbolos extra añadidos. Se publicó su primera revisión en 1985.
Esta codificación es conocida en ocasiones como ASCII extendido.
Sin embargo 8 bits siguen siendo insuficientes para codificar todos los alfabetos conocidos, por lo que cada zona tiene que usar su propia especialización de la norma ISO 8859, surgiendo las que listamos a continuación:
- ISO 8859-1 (Latin-1) Europa occidental.
- ISO 8859-2 (Latin-2) Europa occidental y Centroeuropa.
- ISO 8859-3 (Latin-3) Europa occidental y Europa del Sur.
- ISO 8859-4 (Latin-4) Europa occidental y países bálticos (lituano, estonio y lapón).
- ISO 8859-5 Alfabeto cirílico.
- ISO 8859-6 Árabe.
- ISO 8859-7 Griego.
- ISO 8859-8 Hebreo.
- ISO 8859-9 (Latin-5) Europa occidental con el juego de caracteres turco.
- ISO 8859-10 (Latin-6) Europa occidental con juegos de caracteres nórdico, lapón y esquimal.
- ISO 8859-11 Tailandés.
- ISO 8859-13 (Latin-7) Idiomas bálticos y polaco.
- ISO 8859-14 (Latin-8) Idiomas celtas (gaélico, irlandés, escocés, welsh).
- ISO 8859-15 (Latin-9) Añade el símbolo de Euro y otros a ISO 8859-1.
- ISO 8859-16 Idiomas centroeuropeos (polaco, checo, eslovaco, húngaro, albano, rumano, alemán e italiano).
A algunas revisiones se les ha dado un segundo nombre con el que podemos encontrarlo también cuando se hace referencia a él, por ejemplo, al conjunto de caracteres ISO 8859-15 también se le da el nombre Latin-9. En la lista anterior aparecen reflejados.
Unicode
Como solución a los problemas de que ningún conjunto de caracteres recogía todos los lenguajes mundiales, desde 1991 se ha acordado internacionalmente crear y utilizar la norma Unicode, que es una gran tabla, que en la actualidad asigna un código a cada uno de los más de cincuenta mil símbolos que posee, los cuales abarcan todos los alfabetos europeos, ideogramas chinos, japoneses, coreanos, muchas otras formas de escritura, lenguas muertas y más de un millar de símbolos especiales.
Este estándar es mantenido por el Unicode Technical Committee (UTC), integrado en el Unicode Consortium, del que forman parte con distinto grado de implicación empresas como: Microsoft, IBM, Oracle, SAP, Google, instituciones como la Universidad de Berkeley, y profesionales y académicos a título individual.
Unicode para cada carácter o símbolo especifica un nombre y un identificador numérico entero único (llamado el punto de código -code point-) además de otras informaciones necesarias para su uso correcto como la direccionalidad, capitalización y otros atributos.

Ejemplo de carácter Unicode
Según su arquitectura, un ordenador utilizará bloques de 8, 16 o 32 bits para representar dichos números enteros. Las formas de codificación de Unicode reglamentan la forma en que los puntos de código se transformarán en unidades tratables por el computador.
Son tres las formas de codificación bajo el nombre UTF (Unicode Transformation Format - Formato de Transformación Unicode ):
- UTF-8 Codificación orientada a byte con símbolos de longitud variable. La más utilizada pero la más complicada para el ordenador.
- UTF-16 Codificación de 16 bits de longitud variable optimizada para la representación del plano básico multilingüe (BMP).
- UTF-32 Codificación de 32 bits de longitud fija, y la más sencilla de las tres.
Tipografía
Los conjuntos de caracteres ofrecen una tabla con los caracteres y símbolos que pueden manejar y que, por tanto, podemos emplear en el intercambio de información, pero no ofrece ninguna información de cómo esos caracteres y símbolos se representan para que los entienda una persona.
Es por ello que se necesita la tipografía (tipography) o fuentes tipográficas (tipography fonts) para asociar un dibujo a cada carácter o símbolo del conjunto. Es muy importante no confundir la tipografía con los conjuntos de caracteres.
Existen muchísimas fuentes tipográficas, con nombres como Arial o Times, que dibujan una misma letra a base de matrices diferentes y en diferentes estilos; sin embargo, la gran mayoría de las fuentes tipográficas contienen sólo un pequeño subconjunto de todos los que ofrece el conjunto de caracteres.
Ejemplos de uso de los conjuntos de caracteres
A continuación se exponen algunos ejemplos de dónde podemos encontrarnos la utilización de los conjuntos de caracteres para poder hacerse una idea de su utilización.
Páginas HTML
Cuando estamos diseñando una página web con código HTML tenemos que indicarle a través de las etiquetas <meta> el tipo de codificación de caracteres que vamos a utilizar al almacenarla, para que el navegador sepa interpretar los caracteres de manera correcta.
Unos ejemplos de etiquetas serían los siguientes:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
El navegador leerá dicha información y se configurará automáticamente para mostrar el contenido utilizando dicho conjunto de caracteres. En Mozilla Firefox podemos consultar la información de la página y la codificación utilizada como observamos en las siguientes imágenes.
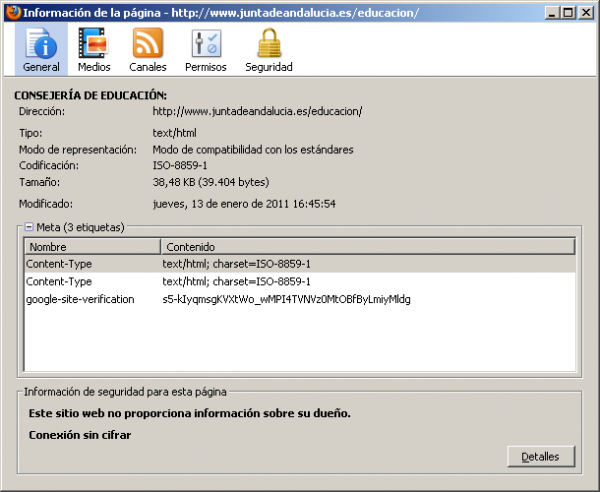
Información de la página en Mozilla Firefox
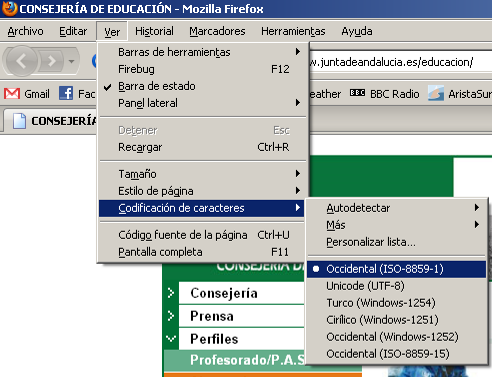
Codificación de caracteres en Mozilla Firefox
Bases de datos en MySQL
Cuando creamos una base de datos debemos de elegir siempre el conjunto de caracteres que se va a utilizar para almacenar la información, pero además es muy importante también elegir el cotejamiento para seleccionar el tipo de ordenación y cómo trabajarán las búsquedas.
El cotejamiento (collation) tiene que ver con el orden que van a tener los caracteres o símbolos dentro de un conjunto de caracteres, y que no tiene que ver con el orden en el que se almacenan dentro del conjunto.
Un sistema de cotejamiento puede ser la ordenación numérica, que fija un orden para los números positivos, negativos, decimales, etc. Otro sistema de cotejamiento puede ser la ordenación alfabética, que fija un orden para las letras del alfabeto. O incluso un sistema de cotejamiento para símbolos como en el caso del lenguaje chino.
El sistema de cotejamiento, a la hora de ordenar palabras, números, etc; indicará si ordenará teniendo en cuenta los caracteres de izquierda a derecha (como en español) o de derecha a izquierda (como en árabe).
Lo normal es que nos encontremos cotejamientos que sean no-sensibles a mayúsculas, minúsculas y acentos (case insensitive - ci) y, por tanto, ordenen al mismo nivel una letra en mayúscula, minúscula y con acento. Aunque también podemos encontrar lo contrario.
Además podemos encontrar que para un mismo conjunto de caracteres existan varios cotejamientos, normalmente según el idioma con el que trabajemos. Por ejemplo, UTF-8 da soporte a casi la totalidad de lenguas del mundo, por lo que existirá un cotejamiento diferente para cada idioma. El carácter Ñ tendrá su sitio solamente en el cotejamiento español (spanish).
En MySQL vienen asociados en cada elección el conjunto con el cotejamiento, por lo que se trata de elegir la adecuada, recordando que la terminación ci significa case insensitive por lo que considerará iguales las letras mayúsculas, minúsculas y con acento.
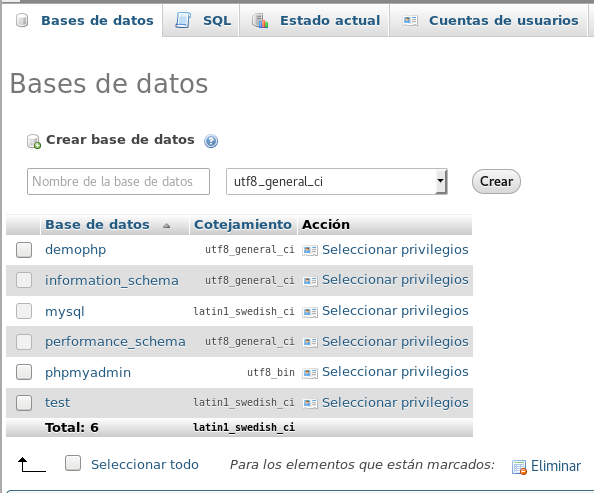
Elegir el cotejamiento en PHPMyAdmin
Sistemas Operativos
Actualmente todos los sistemas operativos Windows, Linux e iOS utilizan el conjunto de caracteres UTF-8 a la hora de almacenar el nombre de archivos y directorios y su contenido en el caso de archivos de texto plano, pero hubo un tiempo en que los sistemas operativos Windows utilizaron el conjunto de caracteres ISO-8859, con la variante específica según el lugar donde se esté utilizando. Estas diferencias hacían que los ficheros creados en un sistema Windows muestren los caracteres de manera diferente en el resto de sistemas operativos.

Qué es la Codificación de Caracteres escrito por Rafa Morales está protegido por una licencia Creative Commons Atribución-NoComercial-SinDerivadas 4.0 Internacional
Codificación de caracteres en Windows y Mac
Interesante artículo para conocer el papel que juegan los diferentes sistemas de codificación de caracteres y, al menos, saber que existen varios de ellos. Casualmente, hace poco tuve que crear un archivo .txt para correr un script asociado a éste. Dicho script corría en un programa diseñado únicamente para Windows. Sin embargo, mi archivo de texto lo creé en Mac. Cual fue mi sorpresa que, aun tratándose de un archivo tan simple, de texto plano, sin formato, etc. Windows desconfiguraba por completo su contenido. Me percaté de que el fallo se debía a algo llamado "codificación de caracteres". Sin embargo, aún no he conseguido averiguar con qué sistema tengo que "recodificar" el .txt creado en Mac para que Windows sea capaz de abrirlo sin problema. ¿Alguna idea?
Gracias ;)
En respuesta a Codificación de caracteres en Windows y Mac por luismorales
Re: Codificación de caracteres en Windows y Mac
Hola Luis,
Resulta que los sistemas operativos Mac y Linux utilizan la codificación de caracteres UTF-8, permitiendo una mayor compatibilidad con todos los sistemas y lenguajes del mundo, pero por el contrario, Windows, se empeña en seguir utilizando por defecto ISO-8859 (o ANSI como lo nombran en sus sistemas). Por eso, al escribir un simple archivo de texto plano en Windows, los caracteres se muestran de manera diferente al abrir ese archivo en Mac o Linux.
Pero la solución es sencilla, si estás escribiendo el archivo con el "Bloc de Notas" o "Wordpad" en Windows, lo único que tienes que hacer es modificar el tipo de codificación a la hora de guardar el documento. Puedes verlo en la siguiente imagen:
Espero que te hayamos podido ayudar un poco.
Saludos.