Qué es XML
XML (eXtensible Markup Language - Lenguaje de Marcas Extensible) no es un lenguaje de marcas en sí, sino un metalenguaje, es decir, XML define las reglas generales que debe cumplir un lenguaje de marcas y la manera de cómo definir dicho lenguaje.
El XML fue creado por el W3C a finales de los 90. El W3C se creó en 1994 para tutelar el crecimiento y organización de la web. Su primer trabajo fue normalizar HTML, el lenguaje de marcas con el que se escriben las páginas web. Al crecer el uso de la web, crecieron las presiones para ampliar el HTML. El W3C decidió que la solución no era ampliar el HTML, sino crear unas reglas para que cualquiera pudiera crear lenguajes de marcas adecuados a sus necesidades, pero manteniendo unas estructuras y sintaxis comunes que permitieran compatibilizarlos y tratarlos con las mismas herramientas. Ese conjunto de reglas es el XML, cuya primera versión se publicó en 1998.
Lógicamente, el HTML no cumple las normas del XML ya que el HTML es anterior al XML. El creador del HTML, Tim Berners-Lee, se basó en el SGML, otro conjunto de reglas para la creación de lenguajes de marcas creado en los años 80 y más complejo que el XML. Una vez creado el XML, el W3C aprobó en el año 2000 el XHTML, una versión del HTML que sí que cumple las reglas del XML. El W3C pretendió sin éxito que el HTML dejara de utilizarse y sólo se utilizara XHTML. Al no conseguirlo, el W3C decidió retomar el desarrollo del HTML (incluyendo en él una versión XHTML). Actualmente, encotnramos ya diseños con la versión 5 de HTML, la cual sigue sin seguir los estándares de XML.
Usos de XML
Todos los usos de XML se basan en el almacenamiento y distribución de información.
- Intercambio de información entre aplicaciones: El hecho de que XML almacene información mediante documentos de texto plano, facilita que se utilice como estándar, ya que no se requiere software especial para leer su contenido, es texto y es entendible por cualquier software.
- Computación distribuida: Se trata de la posibilidad de utilizar XML para intercambiar información entre diferentes computadoras a través de las redes. Las ventajas de XML están relacionadas con el hecho de que con él se crean documentos inocuos (no pueden contener código maligno como virus o espías), con lo que la seguridad de esos sistemas es total.
- Información empresarial: XML es un formato que tiene cada vez más importancia para generar documentos empresariales por la facilidad de estructurar los datos de la forma más apropiada para la empresa. Un documento XML se parece mucho a una pequeña base de datos, con la ventaja de que es muy fácil darle formato de salida por pantalla o impresión.
Conceptos y vocabulario
Documento XML: Un documento XML es un documento de texto plano (sin formato).
Caracteres (characters): Los documentos XML pueden estar codificados en distintos juegos de caracteres (ISO-8859-1, UTF-8, etc). Recomendamos leer Qué es la Codificación de Caracteres.
Procesador XML (XML parser): Cuando una aplicación necesita leer un documento XML, la aplicación recurre a un procesador XML. Este procesador es el que lee el documento, analiza el contenido y le pasa la información en un formato estructurado a la aplicación. La recomendación XML especifica lo que debe hacer el procesador, pero no entra en lo que hace después la aplicación con esa información.
Etiquetas (tags) o Marcas (mark-up): Las etiquetas son marcas que sirven para identificar un contenido concreto del resto del contenido del documento. Una etiqueta empieza con el carácter "<", le continua un nombre identificativo, y termina con el carácter ">". Existen tres tipos de etiquetas:
Etiquetas de apertura (start-tag).
<apartado>
Etiquetas de cierre (end-tag), que empiezan por "/".
</apartado>
Etiquetas vacías (empty-tag), que terminan por "/".
<salto-de-linea />
Elementos (elements): Un elemento es un componente lógico de un documento XML que o bien comienza por una etiqueta de apertura y termina por la etiqueta de cierre correspondiente, o bien consiste en una única etiqueta vacía. El contenido de un elemento es todo lo que se encuentra entre las etiquetas de apertura y cierre, que puede ser texto o incluso otros elementos. También existen elementos vacíos, los cuales no tienen contenido.
Elemento con texto como contenido:
<autor>TicArte</autor>
Elemento con otros elementos como contenido:
<web> <autor>TicArte</autor> </web>
Elemento vacío o sin contenido:
<ingreso />
Los elementos vacíos también pueden encontrarse escritos de esta manera:
<ingreso></ingreso>
Atributos (attributes): Un atributo es un componente de las etiquetas que consiste en una pareja nombre (name) / valor (value). Se puede encontrar en las etiquetas de apertura o en las etiquetas vacías, pero no en las de cierre. En una misma etiqueta no pueden existir dos atributos con el mismo nombre. La sintaxis es siempre nombreAtributo="valorAtributo".
<profesor nombre="Rafael" apellidos="Morales" />
Entidades (entities) y Referencias a entidades: Una entidad consiste en un nombre y su valor (son similares a las constantes en los lenguajes de programación). Las entidades se definen mediante la etiqueta ENTITY.
<!ENTITY web "TicArte">
Una referencia a una entidad empieza con el caracter "&", sigue con el nombre de la entidad y termina con ";". Al abrir el documento XML el procesador sustituye la referencia a la entidad por su valor.
<autor>&web;</autor>
El procesador XML la convertiría en:
<autor>TicArte</autor>
Existen entidades predefinidas, necesarias para poder utilizar los caracteres que delimitan las marcas o las cadenas de texto. Algunas de ellas las podéis ver en la tabla siguiente, el resto de caracteres los tenéis en este enlace.
| Referencia a entidad | Carácter |
| < | < |
| > | > |
| & | & |
| ' | ' |
| " | " |
Instrucciones de procesamiento (PI, processing instruction): Una instrucción de procesamiento en una etiqueta que empieza por "<?" y acaba por "?>" y que contiene instrucciones dirigidas a las aplicaciones que leen el documento. Lo normal es encontrarlas al comienzo del documento.
Para declarar un documento del tipo XML:
<?xml version="1.0" encoding="utf-8"?>
Para asociar una hoja de estilos al documento XML:
<?xml-stylesheet type="text/xsl" href="estilo.xsl" ?>
Comentarios (comments): Un comentario es una etiqueta que comienza por "<!--" y acaba por "-->". Los comentarios no pueden estar dentro de elementos y no pueden contener los caracteres "--". Dentro de un comentario las entidades de carácter no se reconocen, es decir, sólo se pueden utilizar los caracteres del juego de caracteres del documento.
<!-- Esto es un comentario -->
Secciones CDATA (CDATA section): Una sección CDATA es una etiqueta que comienza por "<![CDATA[" y termina por "]]>" y cuyo contenido el procesador XML no interpreta como marcas sino como texto. Es decir que si aparecen los caracteres especiales (< & " ') en una sección CDATA, el procesador XML no interpreta que empieza un marca sino lo considera un carácter más. Se suele utilizar en documentos en los que aparecen muchas veces esos caracteres especiales para no tener que estar utilizando las referencias a entidades (< & " ') que hacen el texto bastante incómodo de leer.
<ejemplo> <![CDATA[ En HTML la negrita se escribe: <strong> ]]> </ejemplo>
Estructura de un documento XML
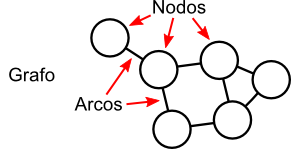
Un documento XML va a tener la estructura lógica de un árbol de nodos, en el que los nodos van a ser los elementos del documento. Para comprender el concepto de árbol, comenzamos explicando el concepto de grafo a partir del cuál se forma.
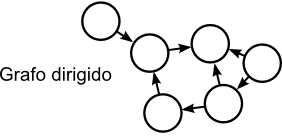
Un grafo es un conjunto de objetos llamados nodos o vértices unidos por enlaces llamados arcos o aristas. Un grafo dirigido es un grafo en el que los arcos indican una dirección.
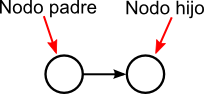
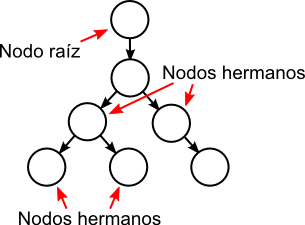
Cuando dos nodos están unidos por un arco con dirección, el nodo padre es el nodo del que parte el arco y el nodo hijo es el nodo al que llega el arco.
Un árbol es un grafo en el que cualquier pareja de nodos están conectada por un único camino (es decir, que no hay ciclos). Un árbol dirigido es un árbol en el que las aristas tienen dirección y todos los nodos menos uno tienen un único padre.

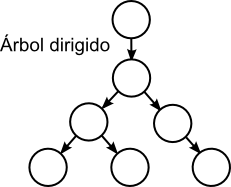
El nodo raíz de un árbol dirigido es el único nodo sin padre. Los nodos hermanos son los nodos que tienen el mismo padre.
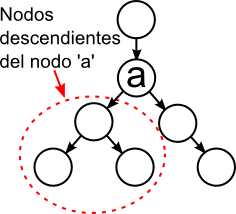
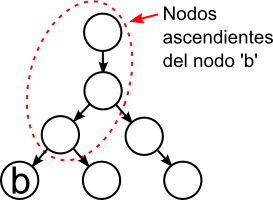
Los nodos descendientes de un nodo son todos los nodos a los que se llega desde el nodo: los hijos, los hijos de los hijos, etc. Los nodos ascendientes de un nodo son todos los nodos de los que un nodo es descendiente: el padre, el padre del padre, etc.
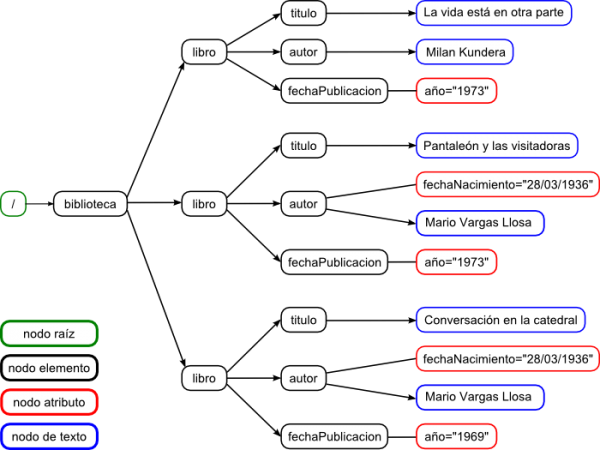
En el siguiente ejemplo de documento XML podemos observar cómo se cumple esta estructura de árbol. El documento comienza con las Instrucciones de Procesamiento, a continuación, aparece el elemento raíz que incluirá al resto de elementos del mismo.
<?xml version="1.0" encoding="UTF-8"?> <biblioteca> <libro> <titulo>La vida está en otra parte</titulo> <autor>Milan Kundera</autor> <fechaPublicacion año="1973"/> </libro> <libro> <titulo>Pantaleón y las visitadoras</titulo> <autor fechaNacimiento="28/03/1936">Mario Vargas Llosa</autor> <fechaPublicacion año="1973"/> </libro> <libro> <titulo>Conversación en la catedral</titulo> <autor fechaNacimiento="28/03/1936">Mario Vargas Llosa</autor> <fechaPublicacion año="1969"/> </libro> </biblioteca>
Validación de documentos
Un documento XML debe validarse, en primer lugar para saber si está bien formado, y en segundo lugar para ver si es válido y cumple las características que le impone el esquema (schema) que pueda tener asociado.
Documentos bien formados
Para que un documento XML se considere "bien formado" (well formed) debe cumplir las reglas de sintaxis de la recomendación XML, entre las que se encuentran las siguientes:
- El documento contiene únicamente caracteres válidos.
- Los caracteres "<" y "&" sólo se utilizan como comienzo de etiquetas.
- Las etiquetas de apertura, de cierre y vacías están correctamente anidadas, es decir, no se solapan. Se deben cerrar primero las etiquetas de los últimos elementos abiertos.
- Hay un elemento raíz que contiene al resto de elementos que forman la estructura de datos de un árbol.
- Los nombres de las etiquetas y de sus atributos comenzarán con una letra, pudiendo utilizarse a continuación más letras, números, guiones altos (-), guiones bajos (_), puntos, pero nunca contandrán espacios en blanco.
- Las etiquetas de cierre coinciden con las de apertura, incluso en el uso de mayúsculas y minúsculas.
- Las etiquetas de cierre no contienen atributos.
- Ninguna etiqueta tiene dos atributos con el mismo nombre.
- El nombre de los atributos sigue las mismas reglas que el nombre de las etiquetas.
- Todos los atributos tienen algún valor.
- Los valores de los atributos están entre comillas, dobles o simples.
- No existen referencias en los valores de los atributos.
Si un documento XML no está bien formado, no se considera un documento XML. Los procesadores XML deben rechazar cualquier documento que contenga errores.
Documentos válidos
Para saber si un documento XML es válido, lo primero que tenemos que conocer es el concepto de esquema.
Esquema (schema): Un esquema es un documento XML que define una gramática con los elementos y atributos que pueden aparecer en el documento XML que la utilice. Esta gramática indicará la secuencia y número de repeticiones de dichos elementos, así como el tipo de contenido que puedan tener esos elementos. Por ejemplo, el esquema de HTML indica que todo documento debe contener un elemento principal <html> y que en su interior existirá un único elemento <head> y a continuación un único elemento <body>.
Por tanto, un documento XML bien formado (condición indispensable) puede ser válido sólo si:
- Incluye una referencia a un esquema (scuema).
- Incluye únicamente elementos y atributos definidos en el esquema.
- Cumple las reglas gramaticales definidas en el esquema.
Existen varias formas de definir un esquema (gramática) para documentos XML, las más empleadas son :
- DTD (Document Type Definition - Definición de Tipo de Documento). Es el modelo más antiguo, heredado del SGML.
- XSD (XML Schema). Es un modelo creado por el W3C como sucesor de las DTDs.
- Relax NG. Es un modelo creado por OASIS, más sencillo que XML Schema.
La mayoría de los programas de tratamiento de lenguajes XML que vamos a nombrar a continuación incluyen su propio validador de documentos. Pero también existen validadores online que realizan la misma función:
Espacios de nombres
Puede ocurrir que cuando se manejan documentos XML puede ocurrir que diferentes XML que tengamos, utilicen las mismas etiquetas. Aunque el contexto sería distinto, tendríamos un problema si manejamos ambos documentos con el mismo software, ya que el analizador, no sabría cómo manejar ambas etiquetas iguales.
Los espacios de nombres (namespacing) evitan el problema indicando en cada etiqueta una código que sirve para indicar el contexto de cada etiqueta y así diferenciar las que son iguales. Ejemplo:
<?xml version="1.0" encoding="UTF-8"?>
<document>
<title>Documento de prueba</title>
<content>
<html>
<head>
<title>Titulo HTML</title>
</head>
<body>
Texto del documento
</body>
</html>
</content>
<author>Jorge</author>
</document> En el ejemplo anterior se usan etiquetas en inglés para el documento (algo muy habitual en el mundo empresarial) y eso hace que la etiqueta "title" se repita en contextos distintos, el primero es para poner un título genérico al documento (y es una etiqueta de la empresa en cuestión) y la segunda se corresponde a la etiqueta "title" del lenguaje HTML (o mejor XHTML).
La solución es anteponer al nombre de la etiqueta un nombre que indique el propietario de la misma por ejemplo:
<?xml version="1.0" encoding="UTF-8"?>
<ticarte.document>
<ticarte.title>Documento de prueba</ticarte.title>
<ticarte.content>
<html>
<head>
<title>Titulo HTML</title>
</head>
<body>
Texto del documento
</body>
</html>
</ticarte.content>
<ticarte.author>Jorge</ticarte.author>
</ticarte.document>
Aunque la mejor solución es incluir en las etiquetas XML el atributo xmlns (xml namespacing) que permite asignar un espacio de nombres a un prefijo en el documento dentro del elemento en el que se usa el espacio de nombres. Ejemplo:
<?xml version="1.0" encoding="UTF-8"?>
<document xmlns:ticarte="http://www.ticarte.com/esquema.xsd"
xmlns:html="htp://www.w3c.org/html">
<ticarte:title>
Documento de prueba
</ticarte:title>
<ticarte:content>
</ticarte:content>
<ticarte:author>
Jorge
</ticarte:author>
</document> En el ejemplo se usa el prefijo "ticarte" para indicar etiquetas del espacio de nombres "http://www.ticarte.com/esquema.xsd" y "html" para el espacio de nombres de HTML.
En el caso de que las etiquetas, mayoritariamente, en un documento pertenezcan a un mismo espacio de nombres, lo lógico es indicar el espacio de nombres por defecto. Eso se hace sin indicar prefijo en el atributo xmlns. Ejemplo:
<?xml version="1.0" encoding="UTF-8"?>
<document xmlns="http://www.ticarte.com/esquema.xsd"
xmlns:html="htp://www.w3c.org/html">
El atributo "xmlns" no tiene por qué utilizarse en el elemento raíz, se puede posponer su declaración en el primer elemento que pertenezca al espacio de nombres deseado. Por ejemplo:
<?xml version="1.0" encoding="UTF-8"?>
<document xmlns="http://www.ticarte.com/esquema.xsd">
<document>
<title>Documento de prueba</title>
<content>
<html:html xmlns:html="htp://www.w3c.org/html">
<html:head>
<html:title>Titulo HTML</html:title>
</html:head>
<html:body>
Texto del documento
</html:body>
</html:html>
</content>
<author>Jorge</author>
</document>
Software para producir documentos XML
En principio XML se puede escribir desde cualquier editor de texto plano (como el Bloc de notas de Windows o el editor nano de Linux). Pero es más interesante hacerlo con un editor que reconozca el lenguaje y que además marque los errores en el mismo.
De hecho el software necesario es el siguiente:
- Un editor de texto plano para escribir el código XML. Bastaría un editor como el Bloc de notas de Windows o el clásico nano de Linux. También son interesantes las opciones de editores capaces de colorear el código como emacs, Notepad++ o SublimeText. Pero la mejor solución son los editores específicos de XML como XML Copy Editor o XMLSpy.
- Un analizador sintáctico o parser, programa capaz de entender y validar el lenguaje XML. Los mismos XML Copy Editor o XMLSpy que ya hemos nombrado.
- Un procesador XML que sea capaz de producir un resultado visual sobre el documento XML. Un simple navegador puede hacer esta función, pero cuando se aplican formatos visuales sobre el documento XML (como los creados mediante XSL) entonces hace falta un software especial que convierta los datos a la forma final visible por el usuario.
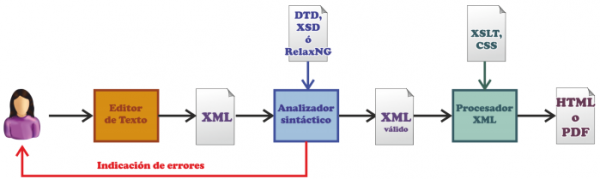
Otras recomendaciones XML
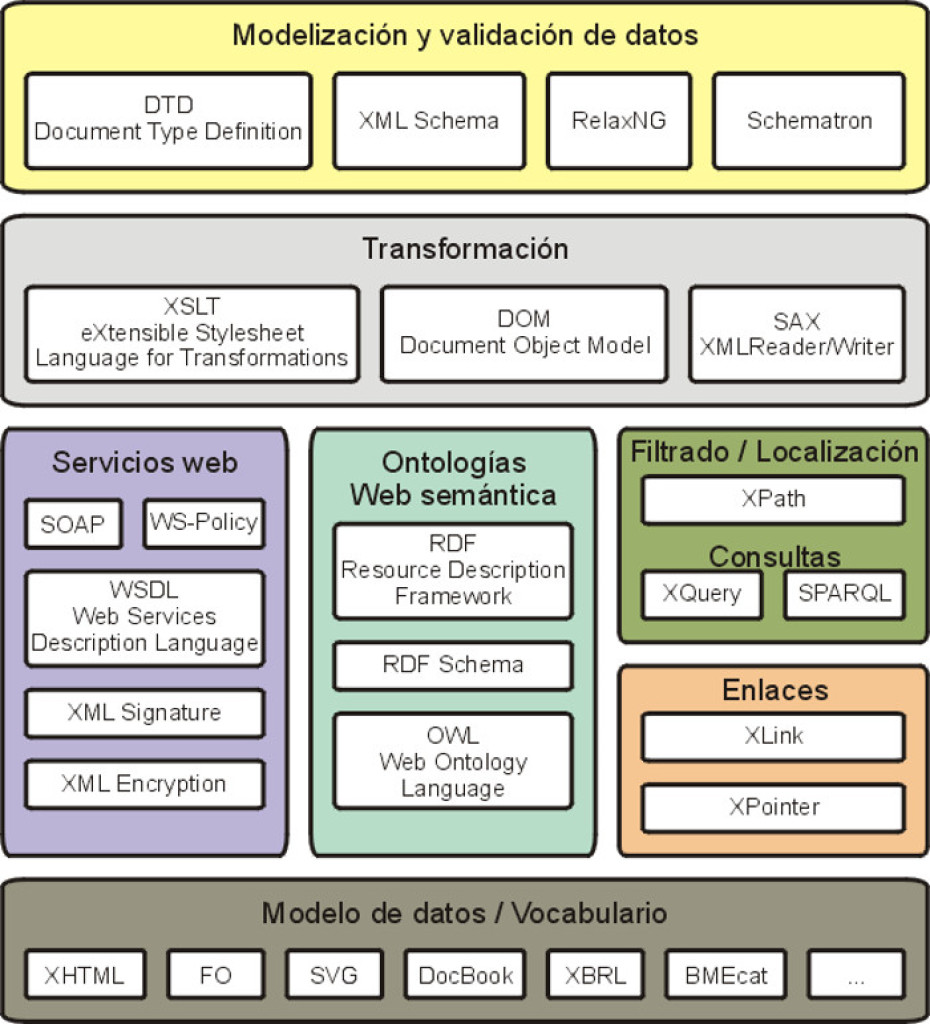
El W3C y otras organizaciones de normalización han publicado numerosas recomendaciones relacionadas con XML. El cuadro siguiente cita algunas de ellas agrupándolas por temas:
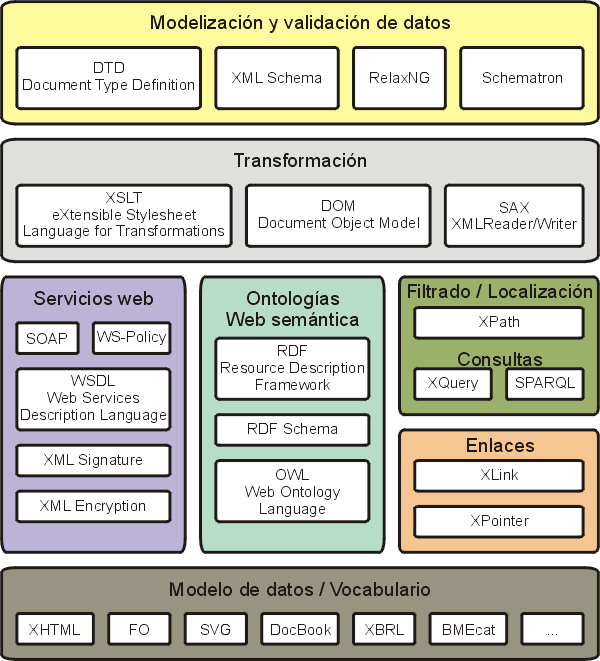
Las más empleadas son las siguientes:
- XML Namespaces: Define los mecanismos para permitir que en un documentos se utilicen elementos y atributos de diferentes vocabularios, sin tener que preocuparse de que algunos nombres coincidan.
- XML Base: Define el atributo xml:base, que puede utilizarse como base para resolver las referencias a URI relativas en un elemento XML.
- XML Infoset: Describe un modelo de datos abstracto para documentos XML a partir de elementos de información. Se utiliza en las especificaciones de lenguajes XML, para describir restricciones en el lenguaje.
- xml:id: Define el atributo id
- XPath: Define las expresiones XPath que sirven para identificar los componentes de un documento XML y facilitar su acceso a los programas que procesan documentos XML.
- XInclude, XLink y XPointer: Sin mucho éxito.
- XSLT: Lenguaje de transformación de documentos XML a otros formatos (XML o no XML)
- XSL Formatting Objects (XSL-FO): Lenguaje de marcas para formatear documentos XML que se usa, por ejemplo, para generar PDFs.
- XQuery: Lenguaje de consulta orientado a XML, que permite acceder, manipular y devolver fragmentos de documentos XML.
- XML Signature: Define la sintaxis y las reglas de procesamiento para crear firmas digitales en documentos XML.
- XML Encryption: Define la sintaxis y las reglas de procesamiento para encriptar documentos XML.
Bibliografía
- Sintes Marco, Bartolomé. "Qué es el XML" y "XPath" del curso "XML: Lenguaje de Marcas Extensible Licencia". Licencia CC BY-CN-SA. [Consulta: Marzo 2014]. http://www.mclibre.org/
-
Sánchez Asenjo, Jorge. Unidad 1 de Lenguajes de Marcas, XML. Versión 2.1 - 2012. Licencia CC BY-CN-SA. [Consulta: Septiembre 2013]. http://www.jorgesanchez.net.
-
TodoXML. https://sites.google.com/site/todoxmldtd/referencia/referencia-de-xml
-
Abrirllave. http://www.abrirllave.com/xml/

Qué es XML escrito por Rafa Morales está protegido por una licencia Creative Commons Atribución-NoComercial-CompartirIgual 4.0 Internacional