Con este artículo sólo pretendremos hacer una pequeña introducción a los Sistemas de Control de Versiones con Git para poder empezar a utilizarlos en tus trabajos de desarrollo. La mayor parte de la información está obtenida de la documentación oficial de Git.
Qué es un Sistema de Control de Versiones
Un Sistema de Control de Versiones (VCS - Version Control System) es un sistema que registra los cambios realizados en un archivo o conjunto de archivos a lo largo del tiempo, de modo que puedas recuperar versiones específicas más adelante. Dicho sistema te permite regresar a versiones anteriores de tus archivos, regresar a una versión anterior del proyecto completo, comparar cambios a lo largo del tiempo, ver quién modificó por última vez algo que pueda estar causando problemas, ver quién introdujo un problema y cuándo, y mucho más.
Los Sistemas de Control de Versiones Distribuidos (DVCS - Distributed Version Control System) permiten que cada cliente tenga una réplica completa del repositorio de trabajo. De esta manera no se depende de un servidor central el cual puede llegar a estar no disponible en algún momento. Además, cualquiera de los repositorios disponibles en los clientes puede ser copiado al servidor con el fin de restaurarlo. Git, Mercurial, Bazaar o Darcs son ejemplo de DVCS.
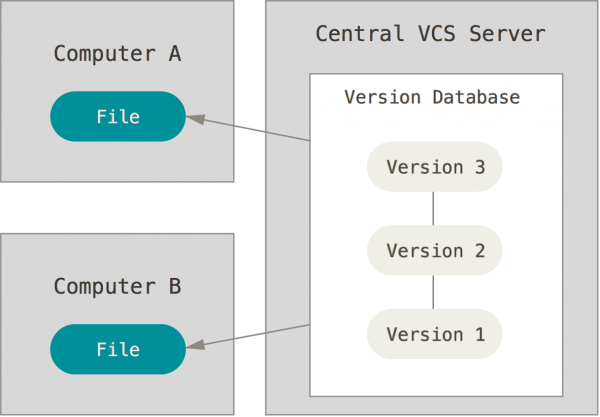
Funcionamiento interno de Git
Git maneja sus datos como un conjunto de copias instantáneas de un sistema de archivos miniatura. Cada vez que confirmas un cambio, o guardas el estado de tu proyecto en Git, él básicamente toma una foto del aspecto de todos tus archivos en ese momento, y guarda una referencia a esa copia instantánea. Para ser eficiente, si los archivos no se han modificado Git no almacena el archivo de nuevo, sino un enlace al archivo anterior idéntico que ya tiene almacenado. Git maneja sus datos como una secuencia de copias instantáneas.
Además todos los cambios son locales y almacenan una suma de comprobación (checksum) para evitar fallos o corrupción en su transmisión.
Git tiene estos estados principales en los que se pueden encontrar tus archivos:
- No modificado (unmodified): el archivo no se ha modificado desde la última confirmación.
- Modificado (modified): el archivo se ha modificado pero todavía no se han confirmado en tu base de datos local.
- Preparado (staged): el archivo se ha modificado y se han marcado en su versión actual para que vaya en la próxima confirmación.
- Confirmado (committed): el archivo está almacenado de manera segura en tu base de datos local.
Esto nos lleva a las tres secciones principales de un proyecto de Git:
- Directorio de Git (Git directory): es donde se almacenan los metadatos y la base de datos de objetos para tu proyecto. Es la parte más importante de Git, y es lo que se copia cuando clonas un repositorio desde otra computadora.
- El directorio de trabajo (working directory): es una copia de una versión del proyecto. Estos archivos se sacan de la base de datos comprimida en el directorio de Git, y se colocan en disco para que los puedas usar o modificar.
- El área de preparación (staging area): es un archivo, generalmente contenido en tu directorio de Git, que almacena información acerca de lo que va a ir en tu próxima confirmación. A veces se le denomina índice (“index”).
El flujo de trabajo básico en Git es algo así:
- Modificas una serie de archivos en tu directorio de trabajo.
- Preparas los archivos, añadiéndolos a tu área de preparación.
- Confirmas los cambios, lo que toma los archivos tal y como están en el área de preparación y almacena esa copia instantánea de manera permanente en tu directorio de Git.
La línea de comandos es la manera más usual de utilizar Git, pero existen muchos IDEs y herramientas gráficas que permiten también realizar las tareas más importantes de Git. Conociendo su línea de comandos sabrás fácilmente cómo utilizar estas herramientas gráficas, pero no al contrario.
Instalación de Git
Git puede instalarse en cualquier sistema operativo, Linux, Windows o Mac. En el siguiente enlace puede encontrar la información detallada del proceso de instalación en cada sistema operativo:
Configuración de Git
Git utiliza tres archivos de configuración, de más global a más específico, que se van sobreescribiendo en ese mismo orden, de más general a más específica:
- /etc/gitconfig | C:\...\gitconfig (system): contiene valores para todos los usuarios del sistema y todos sus repositorios.
- $HOME/.gitconfig | C:\Users\usuario\.gitconfig (global): contiene configuración específica de dicho usuario.
- dir_proyecto/.git/config (local): contiene configuración específica a dicho proyecto de desarrollo.
Podemos mostrar todos los valores de configuración con el siguiente comando. Si aparecen duplicados es porque se están leyendo los mismos valores en diferentes archivos de configuración:
git config --list
Podemos mostrar valores concretos de algún archivo de configuración con los siguientes comandos. Si nos situamos en el directorio del proyecto también aparecerán las directivas de configuración de dicho proyecto:
git config --global --list
git config --system --list
git config --local --list
Lo primero que deberás hacer cuando instales Git es establecer tu nombre de usuario y dirección de correo electrónico. Esto es importante porque las confirmaciones de Git usan esta información, y es introducida de manera inmutable en dichas confirmaciones:
git config --global user.name "John Doe" git config --global user.email johndoe@example.com
Pero si queremos configurarlos de manera local sólo para un proyecto en concreto tendremos que situarnos en el directorio del proyecto en sí y ejecutar:
git config user.name "John Doe" git config user.email johndoe@example.com
Fundamentos de Git
Cómo inicializar un repositorio en un proyecto existente
Si ya tenemos un directorio con nuestro proyecto y queremos crear un repositorio Git a partir de él, lo que demos hacer es ir al directorio de dicho proyecto y ejecutar el siguiente comando:
git init
Esto crea la configuración local del proyecto como hemos nombrado anteriormente, es decir, un subdirectorio nuevo llamado .git, el cual contiene todos los archivos necesarios para mantener dicho repositorio.
Cómo manejar los archivos del repositorio
Por defecto, al inicializar un repositorio, este se encuentra vacío, por lo que tendremos que añadir a él los archivos que queremos que pertenezcan al mismo. Los archivos que añadamos al repositorio se llamarán archivos rastreados (tracked files). El resto de archivos se llamarán archivos sin rastrear (untracked files) y no se almacenarán en el repositorio Git.
Añadimos archivos al repositorio con el siguiente comando:
git add README
git add *.php
git add *
git add .
Una vez que los archivos estén añadidos al repositorio, éstos podrán estar en uno de los estados mencionados anteriormente no modificado, modificado, preparado o confirmado.
Este mismo comando también nos permite pasar los archivos al estado preparado, con lo que estará listo para hacer la confirmación en el repositorio. Por tanto, cada vez que hagamos una modificación a un archivo rastreado tendríamos que ejecutar este comando para pasarlo al estado preparado (pero ya veremos cómo podemos ahorrarnos este paso más adelante). En la siguiente imagen podemos ver el ciclo de vida de un archivo:
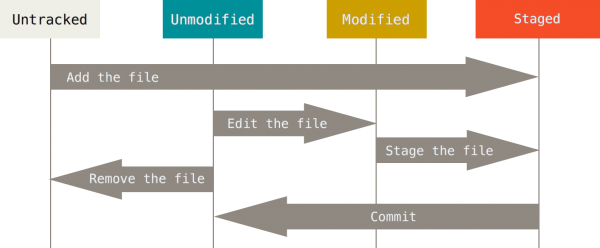
Ciclo de vida del archivo en Git
Con los siguientes comandos de Git podemos eliminar y renombrar un archivo y, al mismo tiempo, pasarlo directamente al estado preparado para su próxima confirmación. Si usamos los comandos del propio sistema operativo se eliminaría también pero no cambiaría el archivo al estado preparado, por lo que perderíamos el historial de cambios de dicho archivo.
git rm main.c
git mv main.c principal.c
A veces tendremos algún tipo de archivo que no deseamos que Git añada automáticamente al repositorio, o más aun, que ni siquiera deseamos que aparezca como no rastreado. Este suele ser el caso de archivos generados automáticamente como logs, configuraciones o temporales del sistema de compilación. En estos casos, podemos crear un archivo llamado .gitignore que liste patrones a considerar. Este es un ejemplo de un archivo:
# ignorar archivos con extensión 'a' *.a # ignorar el directorio raíz /logs /logs # ignorar todos los archivos en el directorio build/ build/ # ignorar todos archivos con extensión 'txt' en ese directorio y todos los subdirectorios doc/**/*.txt
Cómo ver los cambios preparados y no preparados
El comando principal para determinar qué archivos están en qué estado es el comando git status. Si ejecutamos este comando inmediatamente después de clonar o inicializar un repositorio, deberíamos ver algo como esto:
$ git status On branch main nothing to commit, working directory clean
Esto significa que tenemos un directorio de trabajo limpio, es decir, que no hay archivos rastreados y modificados. Por ahora, la rama siempre será main, que es la rama por defecto que suele crearse al inicializar un proyecto, más adelante hablaremos en detalle de ello.
Si añadimos un nuevo archivo a tu proyecto, por ejemplo README, tendríamos el archivo sin rastrear de la siguiente manera:
$ git status On branch main Untracked files: (use "git add <file>..." to include in what will be committed) README nothing added to commit but untracked files present (use "git add" to track)
Existe una opción para obtener un estado abreviado, de manera que podamos ver los cambios de una forma más compacta.
$ git status -s M README MM Rakefile A lib/git.rb M lib/simplegit.rb ?? LICENSE.txt
Los archivos nuevos que no están rastreados tienen un ?? a su lado, los archivos que están preparados tienen una A y los modificados una M. El estado aparece en dos columnas - la columna de la izquierda indica el estado preparado y la columna de la derecha indica el estado sin preparar. Por ejemplo, en esa salida, el archivo README está modificado en el directorio de trabajo pero no está preparado, mientras que el archivo lib/simplegit.rb está modificado y preparado. El archivo Rakefile fue modificado, preparado y modificado otra vez por lo que existen cambios preparados y sin preparar.
Cómo confirmar los cambios
Cuando ya tengamos el área de preparación como deseamos, podemos confirmar los cambios con el siguiente comando, indicando el mensaje de confirmación. Recuerda que una confirmación sería como hacer una instantánea a nuestro repositorio, para poder volver a él cuando lo deseemos. Git utiliza un puntero denominado HEAD que se encarga de apuntar a la confirmación con la que estamos trabajando en este momento.
Toda confirmación lleva un mensaje asociado, te recomendamos leer Cómo escribir un buen mensaje de confirmación.
$ git commit -m "Confirmación inicial" [main 463dc4f] Story 182: Fix benchmarks for speed 2 files changed, 2 insertions(+) create mode 100644 README
A pesar de que puede resultar muy útil para ajustar las confirmaciones tal como queremos, el área de preparación es a veces un paso más complejo a lo que necesitamos para nuestro flujo de trabajo. Si queremos saltarnos el área de preparación, Git nos ofrece un atajo sencillo. Añadiendo la opción -a al comando git commit conseguiremos que Git prepare automáticamente todos los archivos rastreados antes de confirmarlos, ahorrándonos ejecutar previamente el comando git add:
$ git commit -a -m 'Añadido nuevos temporales' [main 83e38c7] added new benchmarks 1 file changed, 5 insertions(+), 0 deletions(-)
Cómo modificar la última confirmación
En ocasiones, tras hacer una confirmación, nos damos cuenta de errores o modificaciones que se nos han olvidado incluir, pero que no quedaría hacer bien otra confirmación sólo para ello. Existe una manera sencilla de modificar la última confirmación realizada, pero debemos entender el problema de realizar este proceso si la confirmación ya ha sido publicada.
Para realizarlo utilizaremos la opción --amend al comando git commit. Añadir el mensaje de confirmación es opcional, pero si no lo hacemos se nos abrirá el editor de texto por defecto con el mensaje de la confirmación para aceptarlo o modificarlo, para evitarlo puede que sea más aconsejable incluirlo de nuevo para sobreescribirlo.
$ git commit -a --amend -m 'Añadido nuevos temporales' [main 1e338c7] added new benchmarks 1 file changed, 1 insertions(+), 0 deletions(-)
Cómo volver a la última confirmación
Si tras nuestro trabajo, hemos comprobado que todas las modificaciones son innecesarias y queremos empezar de nuevo desde la última confirmación, podemos reiniciar nuestro directorio de trabajo y volver al estado de la última confirmación de una manera muy rápida y sencilla.
$ git reset --hard HEAD is now at 1173257 segundo
Cómo ver el historial de confirmaciones
Después de haber hecho varias confirmaciones, o si has clonado un repositorio que ya tenía un histórico de confirmaciones (hablaremos de ello más adelante), probablemente desees mirar atrás para ver qué modificaciones se han llevado a cabo.
La herramienta más básica y potente para hacer esto es el comando git log. Por defecto lista las confirmaciones hechas sobre ese repositorio en orden cronológico inverso, es decir, las confirmaciones más recientes se muestran al principio.
$ git log commit ca82a6dff817ec66f44342007202690a93763949 Author: Scott Chacon <schacon@gee-mail.com> Date: Mon Mar 17 21:52:11 2008 -0700 changed the version number commit 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7 Author: Scott Chacon <schacon@gee-mail.com> Date: Sat Mar 15 16:40:33 2008 -0700 removed unnecessary test
Si queremos visualizar de manera rápida y resumida los cambios introducidos en cada confirmación:
$ git log --stat commit a11bef06a3f659402fe7563abf99ad00de2209e6 Author: Scott Chacon <schacon@gee-mail.com> Date: Sat Mar 15 10:31:28 2008 -0700 first commit README | 6 ++++++ Rakefile | 23 +++++++++++++++++++++++ lib/simplegit.rb | 25 +++++++++++++++++++++++++ 3 files changed, 54 insertions(+)
Y si queremos ver con detalle dichos cambios::
$ git log -p commit ca82a6dff817ec66f44342007202690a93763949 Author: Scott Chacon <schacon@gee-mail.com> +Date: Mon Mar 17 21:52:11 2008 -0700 changed the version number diff --git a/Rakefile b/Rakefile index a874b73..8f94139 100644 --- a/Rakefile +++ b/Rakefile @@ -5,7 +5,7 @@ require 'rake/gempackagetask' - s.version = "0.1.0" + s.version = "0.1.1"
Cómo ver los archivos que incluye una confirmación
Si queremos comprobar la lista de archivos y directorios que incluye una confirmación pasada, lo primero que tendremos que conocer es el identificador de la confirmación deseada, mediante el comando git log. Y posteriormente ejecutar el siguiente comando git ls-tree con el parámetro -r para listar los subdirectorios:
$ git ls-tree -r b0729d58fefb48e45171fcf2b2810f4de1ed6b36 100644 blob 8116e6d91ba6034afb89c4ea2e616805350c45a6 README.md 100644 blob 76adaa83db3bd8cff9ac6a2ff46322a959fb5fd3 connection.php
Cómo etiquetar puntos del historial
Git tiene la posibilidad de etiquetar puntos específicos del historial como importantes. Esta funcionalidad se usa típicamente para marcar versiones de lanzamiento (v1.0, por ejemplo). Existen dos tipos principales de etiquetas:
- Una etiqueta ligera es muy parecido a una rama que no cambia - simplemente es un puntero a una confirmación específica.
- Una etiqueta anotada se guarda en la base de datos de Git como objetos enteros. Tienen un checksum, el nombre del etiquetador, correo electrónico y fecha, un mensaje asociado, y pueden ser firmadas y verificadas con GNU Privacy Guard (GPG). Normalmente se recomiendan las etiquetas anotadas, para almacenar toda esta información.
Para crear una etiqueta ligera en la última confirmación:
git tag v1.4
Para crear una etiqueta anotada en la última confirmación se debe especificar el parámetro -a:
git tag -a v1.4 -m 'Version 1.4'
Para crear una etiqueta ligero o anotada en una confirmación anterior, debemos indicar el número de dicha confirmación:
git tag -a v1.4 -m 'Version 1.4' e8d11a214767768622a1fe594d3ebee674058a61
Para eliminar una etiqueta se debe especificar el parámetro -d:
git tag -d v1.4
Podemos listar las etiquetas disponibles. El siguiente comando las lista en orden alfabético, ya que el orden en el que aparecen no tiene mayor importancia:
$ git tag v0.1 v1.3
Trabajar con repositorios remotos
Hasta este momento, el repositorio Git sólo se encuentra almacenado en nuestro propio ordenador, por lo que sólo nosotros tendremos acceso a él. Para compartir dicho repositorio, ya sea por publicarlo simplemente o por poder trabajar en equipo un grupo de desarrolladores, es necesario incluir los repositorios remotos.
Un repositorio remoto es aquel que está alojado en un equipo diferente al tuyo, ya sea en algún servicio de Internet o en un servidor de la red local de tu organización.
Cómo iniciar un repositorio remoto
Cuando ya tenemos un repositorio local y queremos añadirle un repositorio remoto para sincronizarlo, el primer paso será crear en el servicio remoto dicho repositorio vacío, sin ningún archivo incluido, para que seamos nosotros los que subamos el contenido desde nuestro repositorio local.
Los servicios como Github, Bitbucket o Gitlab te dan la URL que debes utilizar al trabajar con repositorios remotos.
Los pasos que debemos realizad son los siguientes (no explicaremos los pasos que han sido ya tratados anteriormente):
1) Iniciar el proyecto con el comando git init.
2) Añadir los archivos al repositorio con el comando git add.
3) Tener realizadas una o más confirmaciones con el comando git commit.
4) Añadir la referencia al repositorio remoto con el comando git remote, al que habrá que especificarle un alias y la URL del mismo. Por defecto se suele utilizar el alias origin.
git remote add origin https://rafaticarte@github.com/rafaticarte/demophp.git
Podemos renombrar el alias del repositorio remoto:
$ git remote rename origin github github https://github.com/rafaticarte/demophp (fetch) github https://github.com/rafaticarte/demophp (push)
Y también podemos listar los remotos asociados, ya que pueden ser más de uno:
$ git remote -v origin https://github.com/rafaticarte/demophp (fetch) origin https://github.com/rafaticarte/demophp (push)
5) Subir los cambios del repositorio local al repositorio remoto indicando el alias del remoto y la rama con el comando git push:
git push origin main
6) En el caso de trabajar desde diferentes ordenadores o trabajar en equipo en el mismo repositorio, el repositorio remoto puede poseer confirmaciones que no poseamos nosotros en nuestro repositorio local, por tanto, será necesario descargar y fusionar el repositorio remoto con el nuestro local, para ello indicamos el alias del remoto y la rama con el comando git pull. Si tuviéramos cambios en los archivos de nuestro repositorio local, se nos indicará que debemos resolver manualmente estos conflictos.
git pull origin main
Recomendación! Antes de hacer una nueva confirmación en el repositorio local, debemos hacer siempre un git pull para descargar y fusionar todas las actualizaciones del remoto. Si realizáramos una confirmación sin traernos previamente con git pull las actualizaciones, y luego nos encontráramos que existen nuevas confirmaciones en el remoto, la resolución de este conflicto ya es un poco más compleja y no entraría en el nivel de dificultad que perseguimos con este manual.
Reseñar que el comando git pull es como realizar seguidos los comandos git fetch y git merge (más información):
- git pull: se descarga los cambios del repositorio remoto y actualiza el directorio de trabajo.
- git fetch: se descarga los cambios del repositorio remoto, pero no actualiza el directorio de trabajo.
- git merge: fusiona los cambios (hablaremos más adelante de este comando).
En la siguiente imagen vemos el flujo de trabajo con el repositorio remoto.
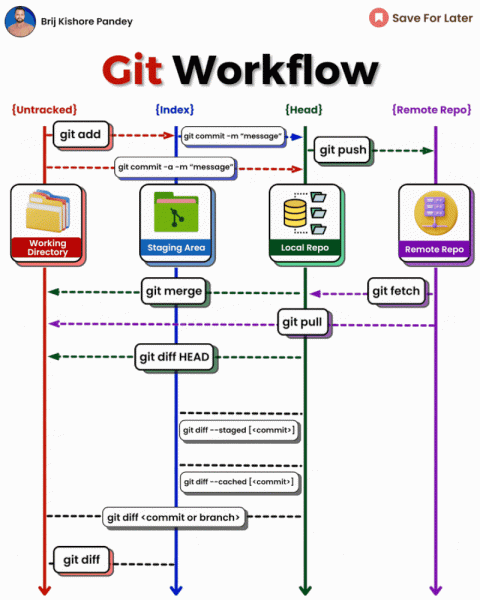
Flujo con repositorios remotos (imagen de Brij Jishore)
Cómo descargar un repositorio remoto existente
Si deseamos obtener una copia de un repositorio remoto podemos utilizar el comando git clone. De esta manera se recibe una copia completa del repositorio con cada versión de cada archivo de la historia del repositorio.
git clone https://github.com/rafaticarte/demophp
Esto crea un directorio llamado demophp, en su interior crea otro nuevo directorio llamado .git, en él descarga toda la información de ese repositorio y saca una copia del directorio de trabajo de la última versión.
Si queremos clonar el repositorio en un directorio con otro nombre, podemos especificarlo con la siguiente opción:
git clone https://github.com/rafaticarte/demophp proyecto_demo_php
En el caso de ser un repositorio privado, nos pedirá autenticarnos para poder descargarlo. En este caso la URL suele venir acompañada del usuario con permisos en dicho repositorio:
$ git clone https://rafaticarte@github.com/rafaticarte/demophp Clonar en «demophp»... Password for 'https://rafaticarte@github.com':
Cómo trabajar con etiquetas y repositorios remotos
Por defecto, el comando git push no transfiere las etiquetas a los repositorios remotos. Debemos subir las etiquetas de forma explícita con el mismo nombre que la hayamos creado.
$ git push origin v1.5 Counting objects: 14, done. Delta compression using up to 8 threads. Compressing objects: 100% (12/12), done. Writing objects: 100% (14/14), 2.05 KiB | 0 bytes/s, done. Total 14 (delta 3), reused 0 (delta 0) To git@github.com:schacon/simplegit.git * [new tag] v1.5 -> v1.5
Pero si queremos subir varias etiquetas a la vez, podemos utilizar la opción --tags del comando. Esto enviará al repositorio remoto todas las etiquetas que aun no existen en él.
$ git push origin main --tags Counting objects: 1, done. Writing objects: 100% (1/1), 160 bytes | 0 bytes/s, done. Total 1 (delta 0), reused 0 (delta 0) To git@github.com:schacon/simplegit.git * [new tag] v1.4 -> v1.4 * [new tag] v1.4-lw -> v1.4-lw
Con el comando git pull sí que nos traeremos todas las etiquetas del repositorio remoto sin tener que especificarlo con parámetros.
git pull origin main
Ramificaciones en Git
Una rama es un conjunto de confirmaciones que tienen un inicio en la primera confirmación de dicho conjunto. Ya hemos hablado anteriormente que por defecto existe una rama main en cada proyecto. Este nombre, aunque suele ser el que se utiliza por defecto, no tiene por qué ser obligatorio, nosotros podemos elegir el nombre de la rama que deseemos. Por tanto, cada proyecto Git debe poseer como mínimo una rama. A partir de ahí, Git nos da la posibilidad de crear una nueva rama de trabajo desde cualquier confirmación del repositorio. En esa nueva rama podremos crear todas las confirmaciones que deseemos, y puede que siga su flujo de desarrollo de manera independiente o puede que en un determinado punto esta rama fusione su contenido de nuevo con la rama principal, para llegar incluso a desaparecer. Esto nos permite trabajar en nuevas características de nuestra aplicación o en corrección de errores sin tocar la rama principal del proyecto.
Desde la confirmación en la que me encuentre podré crear una nueva rama con el comando git branch:
git branch iss53
Para empezar a trabajar en dicha rama tendremos que movernos a ella, y así Git cambiará el directorio de trabajo a los archivos de dicha rama. Para ello utilizaremos el comando git checkout:
git checkout iss53
Podemos abreviar en un solo comando el proceso de crear la rama y movernos a ella con:
git checkout -b iss53
Podemos ver la lista de ramas de un repositorio con el comando:
git branch
Trabajaremos en la rama iss53 hasta que llegue el momento que nuestro código esté listo y deseemos fusionarlo con la rama main. En este caso, desde la rama main realizaremos dicha fusión con el comando git merge. Por defecto, este comando tomará todas las confirmaciones que hayamos realizado en la rama iss53 y las incluirá en la rama main.
$ git checkout main $ git merge iss53 Updating f42c576..3a0874c Fast-forward index.html | 2 ++ 1 file changed, 2 insertions(+) $ git add * $ git commit -m "Merge iss53"
En la mayoría de ocasiones, lo que desearemos es que en la rama main sólo aparezca una nueva confirmación con la fusión, y no todas las confirmaciones que se hayan realizado en la rama iss53. Para conseguir este efecto, debemos utilizar el parámetro --squash con el comando git merge.
$ git checkout main $ git merge --squash iss53 Updating f42c576..3a0874c Fast-forward index.html | 2 ++ 1 file changed, 2 insertions(+) $ git add * $ git commit -m "Merge iss53"
Pero en ocasiones, nos podemos encontrar que mientras estamos trabajando en la rama iss53, nosotros u otro desarrollador del equipo, ha realizado nuevas confirmaciones en la rama main. En este caso deberíamos fusionar los cambios de rama main en nuestra rama iss53 para continuar trabajando.
$ git checkout iss53 $ git merge --squash main Updating f42c576..3a0874c Fast-forward index.html | 2 ++ 1 file changed, 2 insertions(+) $ git add * $ git commit -m "Merge new commits from main"
Y tanto en un caso como en otro, puede que Git no sepa fusionar de manera automática los cambios generados en la nueva rama. En ese caso nos lo avisará al hacer la fusión:
$ git merge --squash iss53 Auto-fusionando index.html CONFLICTO (contenido): Conflicto de fusión en index.html Commit de squash -- no actualizando HEAD Fusión automática falló; arregle los conflictos y luego realice un commit con el resultado.
Al abrir el archivo en conflicto, Git nos habrá marcado el conflicto entre las marcas HEAD y iss53.
<<<<<<< HEAD ======= <h1>Header</h1> >>>>>>> iss53
Cuando terminemos de trabajar con la rama, si no la necesitamos la podemos eliminar tanto en el repositorio local como en el remoto. Para ellos nos situaremos primeramente en otra rama distinta.
git checkout main git branch -d iss53 git push origin --delete iss53
Si en la rama que deseemos eliminar tenemos confirmaciones sin haber fusionado con la rama padre, tendremos que fusionarlos previamente o forzar la eliminación de la rama sin fusionar.
git checkout main git branch -D iss53
Bibliografía

Control de versiones con Git escrito por Rafa Morales está protegido por una licencia Creative Commons Atribución-NoComercial-CompartirIgual 4.0 Internacional